
Dans cet article Dans cet article
Anthropic a mis en ligne le 30 juin 2026 son nouveau modèle Claude Sonnet 5, présenté comme le Sonnet le plus agentique jamais conçu par le laboratoire. Un modèle agentique, c’est un système capable de planifier, manier des outils et avancer seul sur des tâches longues, là où un simple assistant se contente de répondre à une question. Sonnet 5 vise les performances d’Opus 4.8, le haut de gamme maison, mais à un tarif sensiblement plus bas.
Ce lancement tombe en pleine course à l’agent, où OpenAI comme Google vantent désormais la capacité de leurs modèles à mener des tâches en autonomie. Anthropic ne mise plus sur la puissance brute mais sur le coût, quitte à brader son prix d’entrée. Une interrogation a pourtant émergé dans l’heure suivant l’annonce : à quoi bon un Sonnet moins cher si Opus reste à la fois plus précis et plus rentable ?
Un lancement calibré pour le prix, pas pour les sommets
Sonnet 5 s’affiche à un tarif d’introduction de 2 $ par million de tokens en entrée et 10 $ en sortie jusqu’au 31 août 2026, avant de basculer à 3 $ et 15 $. Opus 4.8 coûte pour sa part 5 $ et 25 $ sur les mêmes volumes. L’écart place Sonnet 5 loin sous le haut de gamme, dans une zone que seuls des modèles plus modestes occupaient jusqu’ici, prolongement direct de sa bascule vers une facturation à l’usage.
Anthropic accompagne pourtant la sortie d’un changement de tokeniseur : à texte identique, Sonnet 5 consomme de 1 à 1,35 fois plus de tokens que son prédécesseur. Une part de la baisse de prix s’en trouve absorbée, l’éditeur présentant lui-même son tarif d’appel comme à peu près neutre pour qui migre depuis le précédent Sonnet. Et c’est justement le graphique censé vendre cette promesse qui a mis le feu aux poudres.
Le graphique coût-performance qui se retourne contre Anthropic
Pour situer son modèle, Anthropic a publié des courbes comparant le coût et la précision de Sonnet 4.6, Sonnet 5 et Opus 4.8 sur la recherche agentique, un test baptisé BrowseComp. Chaque modèle y est mesuré à plusieurs niveaux d’effort, du plus économique au plus poussé, ce qui dessine une frontière coût-performance pour toute la gamme.
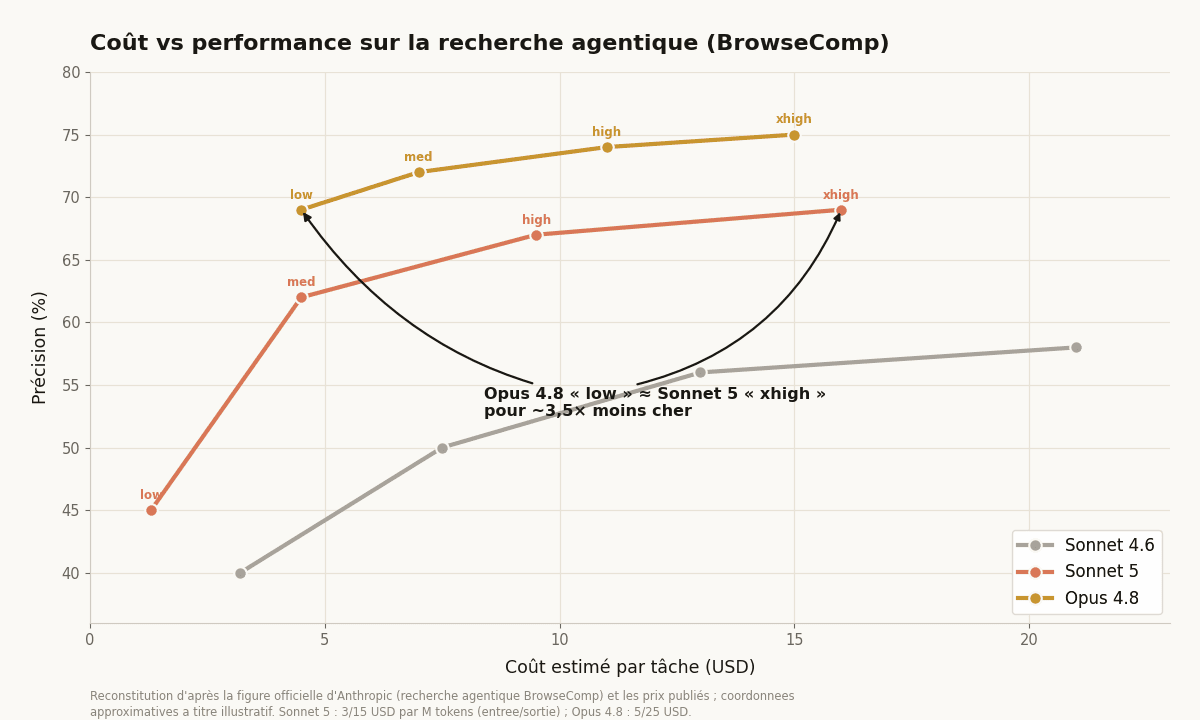
La lecture qui circule est cruelle pour le nouveau venu : au niveau d’effort le plus faible, Opus 4.8 atteint déjà une précision que Sonnet 5 ne touche qu’en mode extrême, pour un coût par tâche environ trois fois et demie supérieur. Aux efforts élevés, Sonnet 5 revient au prix d’Opus tout en restant systématiquement en dessous en qualité, comme le montre le croisement des courbes ci-dessus.
Anthropic ne nie pas cette hiérarchie ; l’éditeur l’assume même noir sur blanc dans son billet de présentation :
Opus 4.8 reste le modèle de choix pour une précision supérieure sur ces tâches, mais Sonnet 5 offre aux développeurs des options moins chères et de bien meilleure qualité que ce qui existait auparavant.
Anthropic, billet de présentation de Claude Sonnet 5, 30 juin 2026
Le créneau réellement défendable se réduit donc aux efforts faibles à moyens, là où Sonnet 5 devient assez bon marché pour du travail d’agent en volume. Le reste de la courbe ne justifie guère son prix face à un Opus 4.8 mieux placé.
Les premiers retours doublent la déception
Sur le forum r/ClaudeAI, le fil consacré à Sonnet 5 a viré au procès en quelques heures, et le résumé automatique de la discussion fait état d’une perplexité quasi unanime. Les reproches se concentrent sur le rapport prix-performance, décliné effort par effort par des développeurs qui ont décortiqué le fameux graphique.
- à effort élevé, Sonnet 5 coûte autant qu’Opus 4.8 pour une précision plus basse, ce qui ôte tout intérêt à ces modes ;
- à effort moyen, il se paie au niveau d’un Opus 4.8 en mode économique, mais reste derrière en qualité ;
- à effort faible, il devient vraiment bon marché, au prix d’un taux de réussite plus bas qui oblige à relancer les tâches ;
- le changement de tokeniseur gonfle la facture réelle d’environ 30 %, ce qui rogne encore l’avantage affiché.
Un testeur résume le verdict dominant d’une formule lapidaire, « pourquoi utiliser ça ? », quand un autre raconte avoir attendu dix-sept minutes pour une tâche bouclée en trois minutes par Opus. Une frange plus nuancée rappelle néanmoins l’évidence : Sonnet 5 remplace Sonnet 4.6, qu’il dépasse à coût égal, et le graphique incriminé ne mesure qu’une seule compétence, la recherche d’informations.
Sonnet 5 face à son propre catalogue
Remis dans la gamme Claude, Sonnet 5 raconte une histoire plus favorable : il améliore nettement Sonnet 4.6 sans toucher au tarif affiché, et talonne Opus 4.8 sur certains usages. Le tableau ci-dessous résume le rapport entre prix et codage agentique pour les trois modèles, d’après les chiffres communiqués par l’éditeur.
| Modèle | Entrée (par M de tokens) | Sortie (par M de tokens) | Codage agentique |
|---|---|---|---|
| Sonnet 4.6 | 3 $ | 15 $ | 58,1 % |
| Sonnet 5 | 2 à 3 $ | 10 à 15 $ | 63,2 % |
| Opus 4.8 | 5 $ | 25 $ | 69,2 % |
Le bond face à Sonnet 4.6 est réel, avec cinq points gagnés en codage agentique à prix d’entrée identique. Opus 4.8 conserve malgré tout six points d’avance, et ne cède du terrain que sur un test de travail intellectuel, où Sonnet 5 le devance d’un cheveu selon Anthropic.
Une fenêtre étroite face à la concurrence
Hors de l’écosystème Anthropic, Sonnet 5 se glisse dans un interstice tarifaire : moins cher qu’Opus 4.8, que le GPT-5.5 d’OpenAI et que le Gemini 3.1 Pro de Google, mais plus cher que le Gemini 3.5 Flash, taillé pour l’agent à bas coût. Le modèle vise une bande de prix très disputée, coincé entre les poids lourds et les options ultra-économiques.
La pression vient aussi des modèles ouverts. Plusieurs développeurs citent GLM, DeepSeek ou Qwen comme offrant aujourd’hui davantage de valeur par euro dépensé, signe que la fidélité à une marque s’érode quand le prix grimpe. Cette nervosité sur les coûts accompagne la généralisation du paiement au token, qui pousse chacun à surveiller sa facture ligne à ligne.
Reste un angle mort dans la démonstration d’Anthropic : l’absence de courbe sur le codage pur, pourtant le cœur de cible de ces modèles. La vitesse d’exécution manque elle aussi à l’appel, alors que plusieurs testeurs décrivent un Sonnet 5 nettement plus rapide, argument qui pourrait justifier son existence pour les flux en temps réel.
Vers une tarification à l’effort plutôt qu’au modèle
Le vrai signal de ce lancement n’est peut-être pas Sonnet 5 lui-même, mais la logique qu’il installe : choisir un niveau d’effort plutôt qu’un modèle. Le curseur de raisonnement devient la variable d’ajustement, et certains utilisateurs anticipent déjà qu’ils piloteront le coût en baissant l’effort d’un gros modèle plutôt qu’en migrant vers un petit.
Cette bascule renvoie à la crainte d’un possible plafond des performances, où empiler de la puissance rapporte de moins en moins. Si la frontière coût-performance se confond d’un modèle à l’autre, la question n’est plus de savoir quel modèle choisir, mais combien on accepte de payer pour quelques points de précision.
Anthropic a donc une démonstration à terminer : prouver, chiffres de codage et de latence à l’appui, que Sonnet 5 occupe une place que ni Opus ni la concurrence ne remplissent mieux. Le marché tranchera sur les tâches réelles des prochaines semaines, là où un graphique de lancement pèse bien peu face à une facture mensuelle.
